
|
I am a final year Ph.D. student at Université de Montréal and Mila advised by Prof. Irina Rish, and closely collaborating with Sanjiban Choudhury.
I am excited about developing agents that interact intelligently with the world to learn how to search, adapt, and recover from mistakes.
Before starting my PhD I was a Data & Applied Scientist at Microsoft and collaborated with Dr. Manik Varma on eXtreme Classification for web-scale recommender systems. I earned my Integrated M.Sc. in Mathematics and Computing from Indian Institute of Technology Kharagpur where I spent time in KRSSG on building autonomous soccer playing robots. |
| |
| [Jun 26] | Excited to share \( \texttt{WEAVER} \) 🌐: a world model for robot manipulation for effective policy evaluation, policy improvement, and test-time planning. |
| [Jun 26] | Excited to share \( \texttt{ARTS} \)--an AI scientist that (i) reasons to guide exploration and (ii) test-time trains to handle long context. |
| [Sep 25] | \( \texttt{SAILOR} \) accepted at NeurIPS 2025 (Spotlight)! |
| [Jul 25] | Had a great time discussing \( \texttt{SAILOR} \) on the RoboPapers podcast. Episode is out! |
| [Jun 25] | Excited to share \( \texttt{SAILOR} \): learning to search for model-based Inverse RL that outperforms Diffusion Policies on visual manipulation tasks. |
| [Mar 25] | \( \mu \texttt{Code} \) accepted at ICML 2025 (Spotlight)! |
| [Feb 25] | Started internship at Cohere with Matthias Gallé on LLM agents for code generation! |
| [Jan 25] | SFM accepted at ICLR 2025! |
| |
|
Abstract /
Paper /
Code /
Website
The potential impacts of world models (WMs, i.e., learned simulators) on robotics are far-reaching--policy evaluation, policy improvement, and test-time planning--all with limited real-world interaction. To unlock these downstream capabilities, a WM needs to jointly satisfy three desiderata: (i) fidelity (i.e., producing simulated trajectories that correlate with reality), (ii) consistency (i.e., producing simulated trajectories that are coherent over long horizons), and (iii) efficiency (i.e., producing simulated trajectories quickly). We propose \( \texttt{WEAVER} \) (World Estimation Across Views for Embodied Reasoning): a WM architecture that simultaneously achieves all three desiderata, providing state-of-the-art results on robotic manipulation tasks. \( \texttt{WEAVER} \) is a multi-view WM trained to predict future latents and reward values via a flow-matching loss. We distill the key design decisions across model architecture, memory, and prediction objectives required to unlock the kinds of long-horizon dynamic manipulation tasks that have confounded prior world modeling approaches. We apply \( \texttt{WEAVER} \) in robotic hardware, demonstrating its effectiveness at policy evaluation (\( \rho = 0.870 \) correlation with real-world success rate), policy improvement (real-world success rate improvement of 38% on top of the \( \pi_{0.5} \) robot foundation model), and test-time planning (real-world success rate improvement of 14% with a \(5-10\times\) speedup over prior WMs). \( \texttt{WEAVER} \) also demonstrates better performance than prior WMs when evaluated on out-of-distribution scenarios. Code, models, and videos at: https://arnavkj1995.github.io/WEAVER/. |
|
|
Abstract /
Paper /
Code /
Website
Scientific discovery can be formulated as an iterative search process over the space of hypotheses and experiments. Contemporary methods navigate this space using heuristics such as MCTS. These algorithms conflate the merit of a hypothesis with the quality of its experimental execution. A promising hypothesis with preliminary execution is therefore ranked below a modest hypothesis whose execution is refined. Moreover, prior methods prune the search logs as the search progresses because the accumulated history outgrows the context window. We propose Agentic Reasoning for Tree Search (\( \texttt{ARTS} \)), where we deploy a reasoning language model to navigate this space. The model inspects prior execution logs, diagnoses whether earlier failures arose from faulty implementations or bad hypotheses, and selects the hypothesis to build on next. To mitigate challenges with context length, \( \texttt{ARTS} \) uses test-time training to instill the knowledge of search tree in the model weights. Across 22 tasks from MLGym and MLEBench, we show that \( \texttt{ARTS} \) outperforms leading algorithms, with over 15.3% relative improvement in the normalized score. With test-time training we show that a Qwen3-4B agent can match performance with closed-source frontier models like Gemini-3 Pro and GPT o3-reasoning with upto 5x lower inference cost. We further observe that on partially observable RL tasks, the test-time trained Qwen3-4B scientist surpasses \( \texttt{ARTS} \) with the o3 scientist by rediscovering the human-best recurrent-memory solution that heuristic methods prune away. |
|
 |
Embodied World Models Workshop, NeurIPS 2025
Abstract /
Paper /
Code /
Website /
Podcast
The fundamental limitation of the behavioral cloning (BC) approach to imitation learning is that it only teaches an agent what the expert did at states the expert visited. This means that when a BC agent makes a mistake which takes them out of the support of the demonstrations, they often don’t know how to recover from it. In this sense, BC is akin to giving the agent the fish – giving them dense supervision across a narrow set of states – rather than teaching them to fish: to be able to reason independently about achieving the expert’s outcome even when faced with unseen situations at test-time. In response, we explore learning to search (L2S) from expert demonstrations, i.e. learning the components required to, at test time, plan to match expert outcomes, even after making a mistake. These include (1) a world model and (2) a reward model. We carefully ablate the set of algorithmic and design decisions required to combine these and other components for stable and sample/interaction-efficient learning of recovery behavior without additional human corrections. Across a dozen visual manipulation tasks from three benchmarks, our approach SAILOR consistently out-performs state-of-the-art Diffusion Policies trained via BC on the same data. Furthermore, scaling up the amount of demonstrations used for BC by 5-10× still leaves a performance gap. We find that SAILOR can identify nuanced failures and is robust to reward hacking. Our code is available at https://github.com/arnavkj1995/SAILOR. |
 |
Verif-AI, SSI-FM, Reasoning and Planning Workshops @ ICLR, 2025
Abstract /
Paper /
Code /
Website
We address the problem of code generation from multi-turn execution feedback. Existing methods either generate code without feedback or use complex, hierarchical reinforcement learning to optimize multi-turn rewards. We propose a simple yet scalable approach, \( \mu \texttt{Code} \), that solves multi-turn code generation using only single-step rewards. Our key insight is that code generation is a one-step recoverable MDP, where the correct code can be recovered from any intermediate code state in a single turn. \( \mu \texttt{Code} \) iteratively trains both a generator to provide code solutions conditioned on multi-turn execution feedback and a verifier to score the newly generated code. Experimental evaluations show that our approach achieves significant improvements over the state-of-the-art generator-verifier baselines. We provide analysis of the design choices of the reward models and policy, and show the efficacy of \( \mu \texttt{Code} \) at utilizing the execution feedback. |
 |
Models of Human Feedback for AI Alignment Workshop @ ICML, 2024
Abstract /
Paper /
Code /
Website
In inverse reinforcement learning (IRL), an agent seeks to replicate expert demonstrations through interactions with the environment. Traditionally, IRL is treated as an adversarial game, where an adversary searches over reward models, and a learner optimizes the reward through repeated RL procedures. This game-solving approach is both computationally expensive and difficult to stabilize. Instead, we embrace a more fundamental perspective of IRL as that of state-occupancy matching: by matching the cumulative state features encountered by the expert, the agent can match the returns of the expert under any reward function in a hypothesis class. We present a simple yet novel framework for IRL where a policy greedily matches successor features of the expert where successor features efficiently compute the expected features of successive states observed by the agent. Our non-adversarial method does not require learning a reward function and can be solved seamlessly with existing value-based reinforcement learning algorithms. Remarkably, our approach works in state-only settings without expert action labels, a setting which behavior cloning (BC) cannot solve. Empirical results demonstrate that our method learns from as few as a single expert demonstration and achieves comparable performance on various control tasks. |
 |
Frontiers4LCD Workshop @ ICML, 2023
Abstract /
Paper /
Code
Animals have a developed ability to explore that aids them in important tasks such as locating food, exploring for shelter, and finding misplaced items. These exploration skills necessarily track where they have been so that they can plan for finding items with relative efficiency. Contemporary exploration algorithms often learn a less efficient exploration strategy because they either condition only on the current state or simply rely on making random open-loop exploratory moves. In this work, we propose ηψ-Learning, a method to learn efficient exploratory policies by conditioning on past episodic experience to make the next exploratory move. Specifically, ηψ-Learning learns an exploration policy that maximizes the entropy of the state visitation distribution of a single trajectory. Furthermore, we demonstrate how variants of the predecessor representation and successor representations can be combined to predict the state visitation entropy. Our experiments demonstrate the efficacy of ηψ-Learning to strategically explore the environment and maximize the state coverage with limited samples.
@inproceedings{
jain2023maximum,
title={Maximum State Entropy Exploration using Predecessor and Successor Representations},
author={Arnav Kumar Jain and Lucas Lehnert and Irina Rish and Glen Berseth},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=tFsxtqGmkn}
}
|
 |
DeepRL Workshop @ NeurIPS, 2021
Abstract /
Paper /
Code
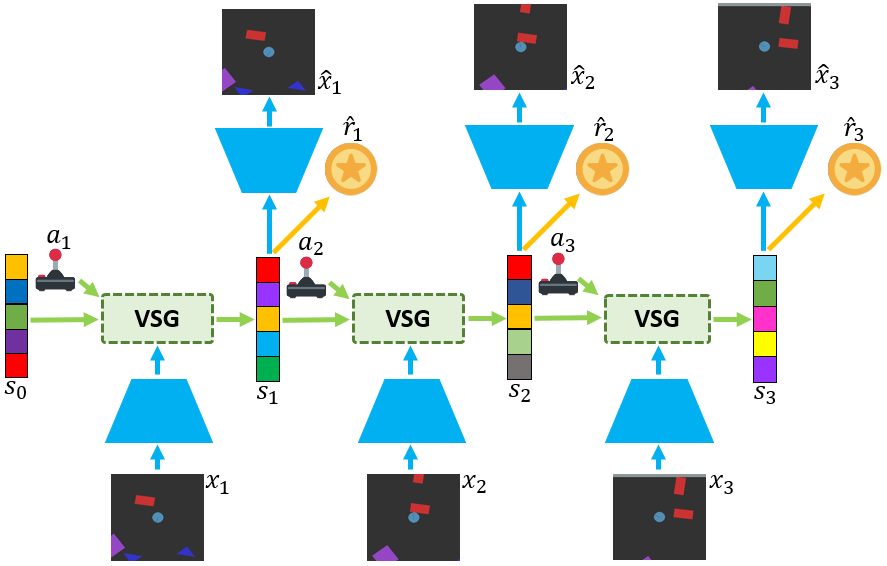
Learning world models from their sensory inputs enables agents to plan for actions by imagining their future outcomes. World models have previously been shown to improve sample-efficiency in simulated environments with few objects, but have not yet been applied successfully to environments with many objects. In environments with many objects, often only a small number of them are moving or interacting at the same time. In this paper, we investigate integrating this inductive bias of sparse interactions into the latent dynamics of world models trained from pixels. First, we introduce Variational Sparse Gating (VSG), a latent dynamics model that updates its feature dimensions sparsely through stochastic binary gates. Moreover, we propose a simplified architecture Simple Variational Sparse Gating (SVSG) that removes the deterministic pathway of previous models, resulting in a fully stochastic transition function that leverages the VSG mechanism. We evaluate the two model architectures in the BringBackShapes (BBS) environment that features a large number of moving objects and partial observability, demonstrating clear improvements over prior models.
@InProceedings{Jain22,
author = "Jain, A.~K. and Sujit, S. and
Joshi, S. and Michalski, V.
and Hafner, D. and Kahou, S.~E.",
title = "Learning Robust Dynamics through
Variational Sparse Gating",
booktitle = {Advances in
Neural Information Processing Systems},
month = {December},
year = {2022}
}
|
 |
Abstract /
Paper /
Code
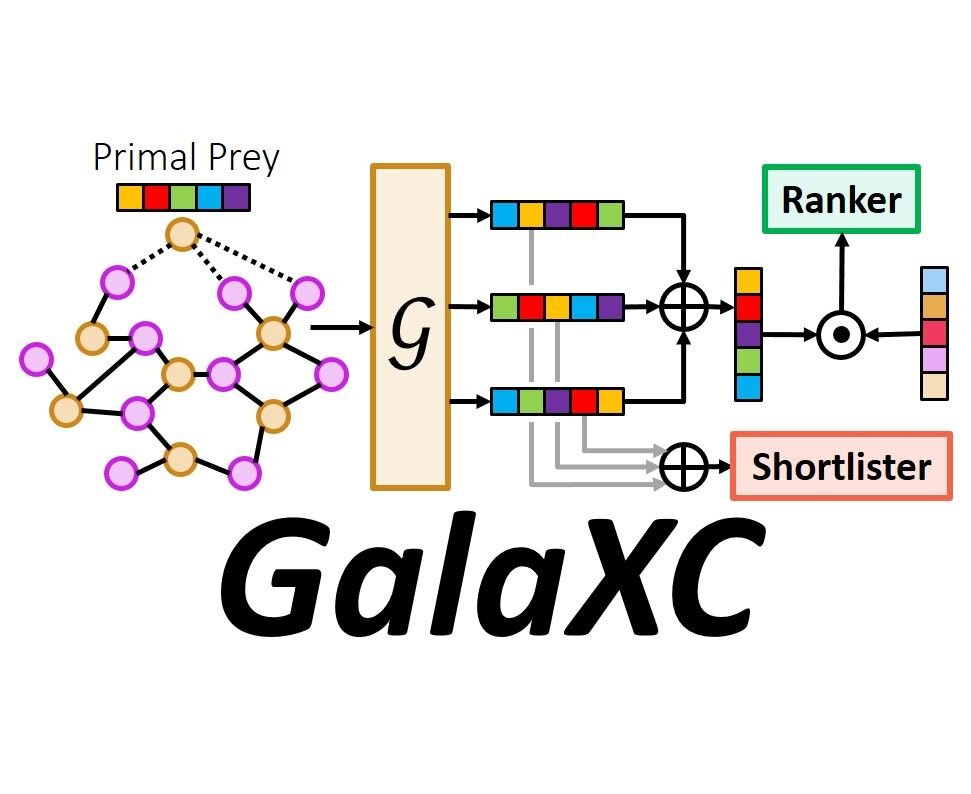
This paper develops the GalaXC algorithm for Extreme Classification, where the task is to annotate a document with the most relevant subset of labels from an extremely large label set. Extreme classification has been successfully applied to several real world web-scale applications such as web search, product recommendation, query rewriting, etc. GalaXC identifies two critical deficiencies in leading extreme classification algorithms. First, existing approaches generally assume that documents and labels reside in disjoint sets, even though in several applications, labels and documents cohabit the same space. Second, several approaches, albeit scalable, do not utilize various forms of metadata offered by applications, such as label text and label correlations. To remedy these, GalaXC presents a framework that enables collaborative learning over joint document-label graphs at massive scales, in a way that naturally allows various auxiliary sources of information, including label metadata, to be incorporated. GalaXC also introduces a novel label-wise attention mechanism to meld high-capacity extreme classifiers with its framework. An efficient end-to-end implementation of GalaXC is presented that could be trained on a dataset with 50M labels and 97M training documents in less than 100 hours on 4xV100 GPUs. This allowed GalaXC to not only scale to applications with several millions of labels, but also be up to 18% more accurate than leading deep extreme classifiers, while being upto 2-50x faster to train and 10x faster to predict on benchmark datasets. GalaXC is particularly well-suited to warm-start scenarios where predictions need to be made on data points with partially revealed label sets, and was found to be up to 25% more accurate than extreme classification algorithms specifically designed for warm start settings. In A/B tests conducted on the Bing search engine, GalaXC could improve the Click Yield (CY) and coverage by 1.52% and 1.11% respectively. Code for GalaXC is available at https://github.com/Extreme-classification/GalaXC.
@InProceedings{Saini21,
author = "Saini, D. and Jain, A.~K. and Dave, K.
and Jiao, J. and Singh, A. and Zhang, R.
and Varma, M.",
title = "GalaXC: Graph neural networks with
labelwise attention for extreme classification",
booktitle = "Proceedings of The ACM International
World Wide Web Conference",
month = "April",
year = "2021",
}
|
 |
Abstract /
Paper /
Slides
Contemporary deep learning based semantic inpainting can be approached from two directions. First, and the more explored, approach is to train an offline deep regression network over the masked pixels with an additional refinement by adversarial training. This approach requires a single feed-forward pass for inpainting at inference. Another promising, yet unexplored approach is to first train a generative model to map a latent prior distribution to natural image manifold and during inference time search for the `best-matching' prior to reconstruct the signal. The primary aversion towards the latter genre is due to its inference time iterative optimization and difficulty to scale to higher resolution. In this paper, going against the general trend, we focus on the second paradigm of inpainting and address both of its mentioned problems. Most importantly, we learn a data driven parametric network to directly predict a matching prior for a given masked image. This converts an iterative paradigm to a single feed forward inference pipeline with around 800x speedup. We also regularize our network with structural prior (computed from the masked image itself) which helps in better preservation of pose and size of the object to be inpainted. Moreover, to extend our model for sequence reconstruction, we propose a recurrent net based grouped latent prior learning. Finally, we leverage recent advancements in high resolution GAN training to scale our inpainting network to 256x256. Experiments (spanning across resolutions from 64x64 to 256x256) conducted on SVHN, Standford Cars, CelebA, CelebA-HQ and ImageNet image datasets, and FaceForensics video datasets reveal that we consistently improve upon contemporary benchmarks from both schools of approaches..
@inproceedings{lahiri2020prior,
title = {Prior Guided GAN Based Semantic Inpainting},
author = {Lahiri, Avisek and Jain, Arnav Kumar and Agrawal,
Sanskar and Mitra, Pabitra and Biswas, Prabir Kumar},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition},
pages = {13696--13705},
year = {2020}
}
|